DIPLOMOVÁ PRÁCE
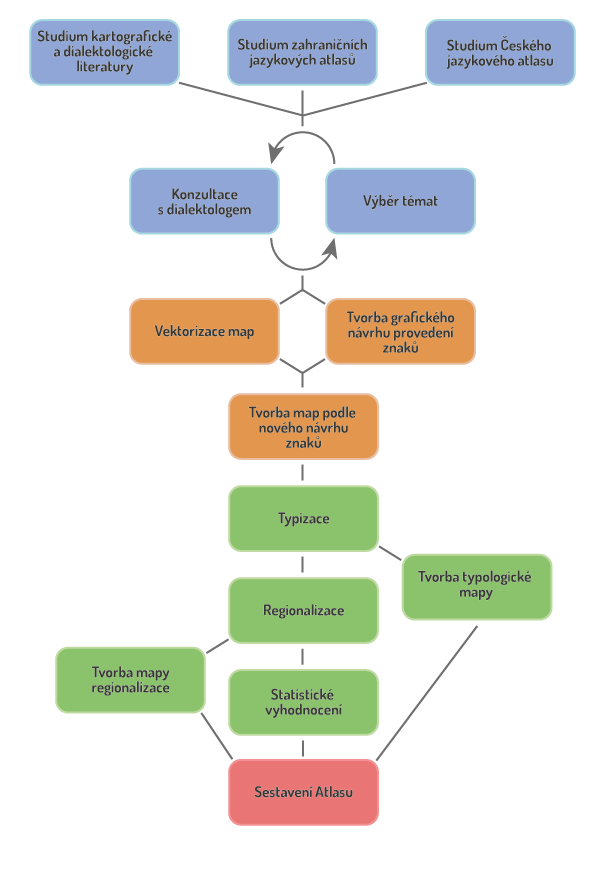
Schéma postupu zpracování práce
V přípravné fázi práce zahrnovala studium relevantních materiálů, mezi nimiž je základem ČJA. Dále byly studovány zahraniční jazykové atlasy, např. Atlas slovenského jazyka (Štolc et al. 1984). Poznatky z porovnání tuzemských a zahraničních jazykových atlasů byly vstupem do procesu tvorby nových map. Studována byla také literatura zaměřená na dialektologii či lingvistiku společně s odbornými články a publikacemi, jež se zabývají tématikou kartografie.
Po konzultacích s dialektologem proběhl výběr témat z ČJA určených k dalšímu zpracování. Následně proběhla vektorizace map zvolených podle vydefinovaných kritérií, a to do formátu vhodného k dalšímu zpracování v GIS. Postup vektorizace je detailněji popsán v kapitole 6.
Následně byl vytvořen grafický návrh podoby znaků pro vektorizované mapy. Výsledkem je sada symbolů uložených jako styl v softwaru ArcGIS Pro. Podle tohoto návrhu byly následně vypracovány analytické nářeční mapy pro vybraných 16 slov. Mapy byly zpracovány do kompozice odpovídající požadavkům pro tvorbu atlasu.
Poté následovalo sestavení typologie, které proběhlo v prostředí ArcGIS Pro. Data vstupující do typizace, musela být nejdříve upravena do požadované podoby, následně byla provedena překryvná analýza, jejíž výsledky byly v dalším kroku generalizovány. V další fázi byla generalizovaná data kvantifikována. Tato data byla přenesena do prostředí MS Excel, ve kterém byl vytvořen vzorec pro sečtení hodnot do jednoho atributu. Z výsledných hodnot byly poté sestaveny intervaly, podle kterých byly vymezeny jednotlivé typy krácení vokálů. Následně byla sestavena mapa typů vycházející z vytvořené typologie.
Další fází bylo vytvoření regionalizace krácení vokálů. Výchozími daty byla typologie vytvořená v předešlém kroku. K tvorbě regionalizace byla zvolena metoda vizuální analýzy, pomocí které byla nejdříve nalezena jádra, podle kterých byly následně zakresleny hranice regionů. Po jejím dokončení byla na základě výsledku sestavena mapa regionalizace.
Po zpracování syntetické části práce proběhlo statistické vyhodnocení výsledné typologie a regionalizace. To bylo rozděleno na tři části. V první byl vypočítán podíl obyvatel nacházejících se v oblastech jednotlivých typů a regionů. Data o počtu obyvatel byla odvozena ze Sčítání lidí domů a bytů z roku 2011 prostřednictvím digitální vektorové databáze ArcČR 500. Hodnoty obyvatel byly vztahovány k obcím, nicméně započítávány byly pouze ty lokality, které se nacházely v území s provedeným dialektologickým výzkumem. Obce, které nebyly započteny, se zpravidla nacházely v pohraničních oblastech. Druhou částí bylo vypočtení podílu prostorového rozložení výsledných typů a regionů v rámci celé ČR. Rozloha byla počítána na úrovni obcí, také z databáze ArcČR 500 (ARCDATA PRAHA 2016). Poslední částí bylo vypočtení podílu zastoupení jednotlivých typů a regionů v rámci oblastí nářečí českého jazyka.
Posledním krokem této práce bylo sestavení atlasu s názvem „Atlas nářečí českého jazyka: krácení vokálů.“ Do něj byly zahrnuty analytické a syntetické nářeční mapy. Ke každé mapě byly vytvořeny infografiky zobrazující zjištěné statistické údaje. Atlas byl zpracován v programu Adobe Illustrator CS6, ve kterém bylo vytvořeno celkem 54 stran, na kterých se nacházelo 32 map.