Hodnocení distribuce populace z dat mobilního operátora
Bakalářská práce
Autor: Vojtěch Svoboda
Olomouc 2025
Úvod
Použité metody
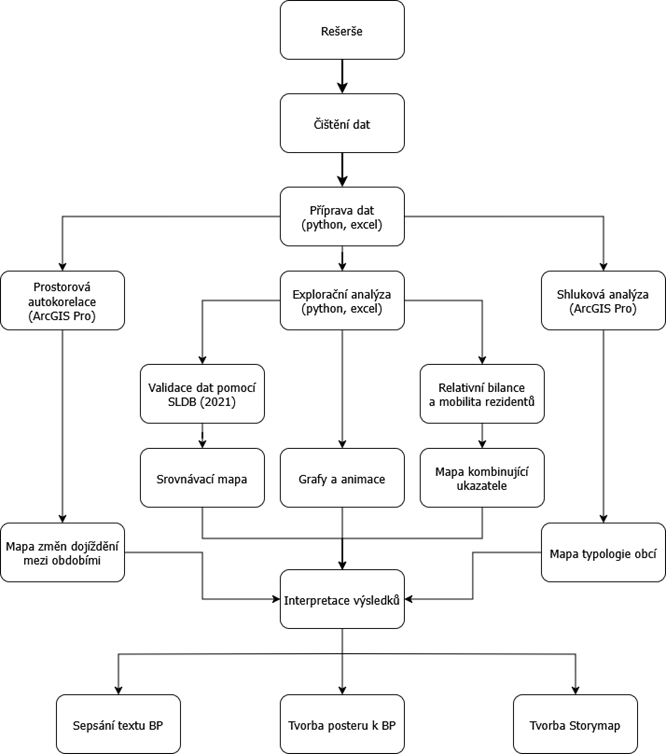
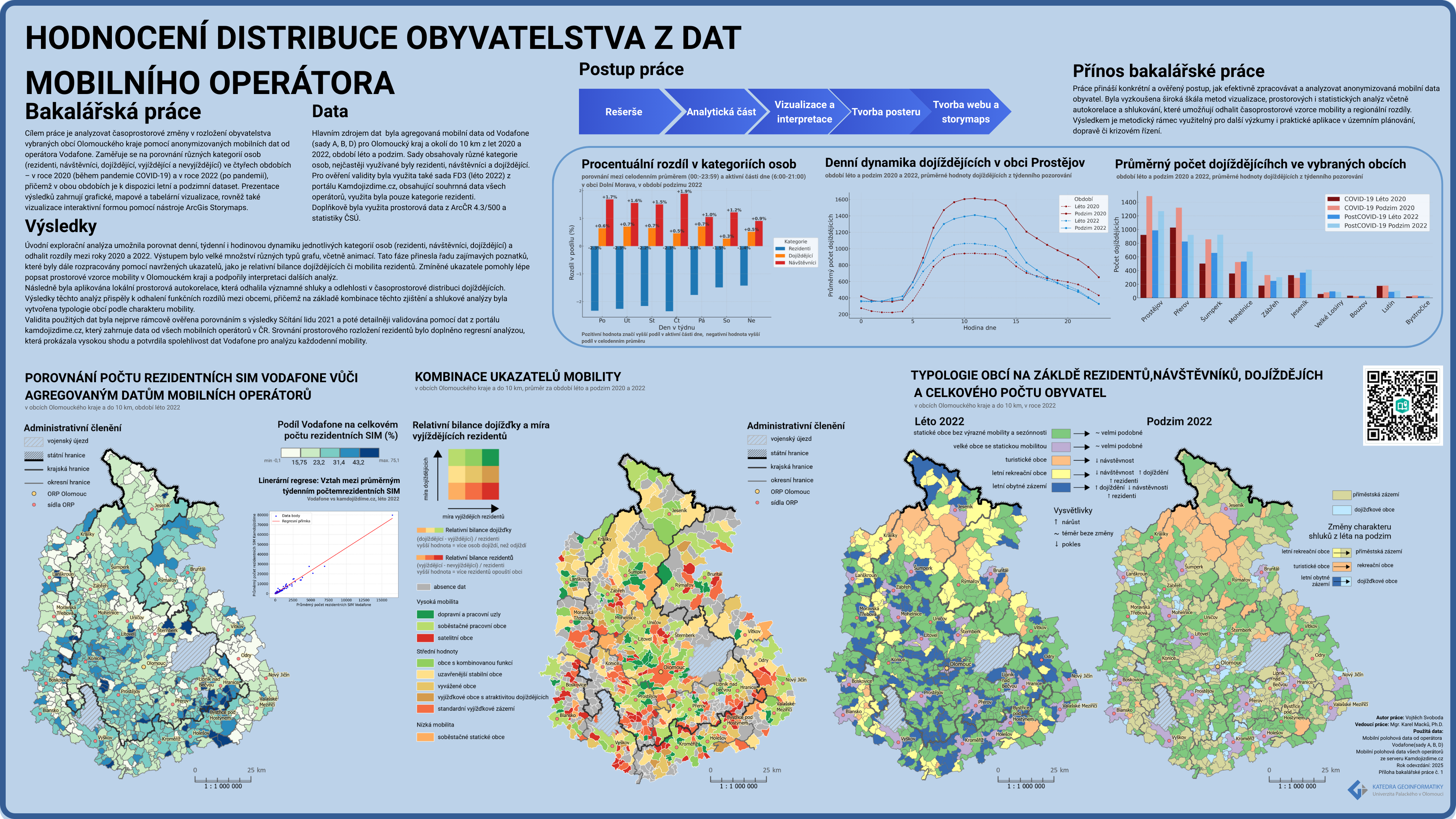
V této práci byly aplikovány teoretické a kvantitativní metody analýzy dat. Po základním čištění a transformaci dat byla provedena explorační analýza (EDA), která odhalila sezónní trendy, vzorce a rozdíly v prostorovém a časovém rozložení kategorií osob. Dále byla použita analýza prostorové autokorelace pomocí lokálního Moranova indexu, která identifikovala významné prostorové shluky a outliery. Kombinace explorační analýzy a metod multivariační shlukové analýzy byla sestavena typologie obcí a katastrálních území. Validace dat byla provedena porovnáním s referenčními daty ze SLDB 2021 a portálu Kamdojíždíme.
Explorační analýza dat (EDA)
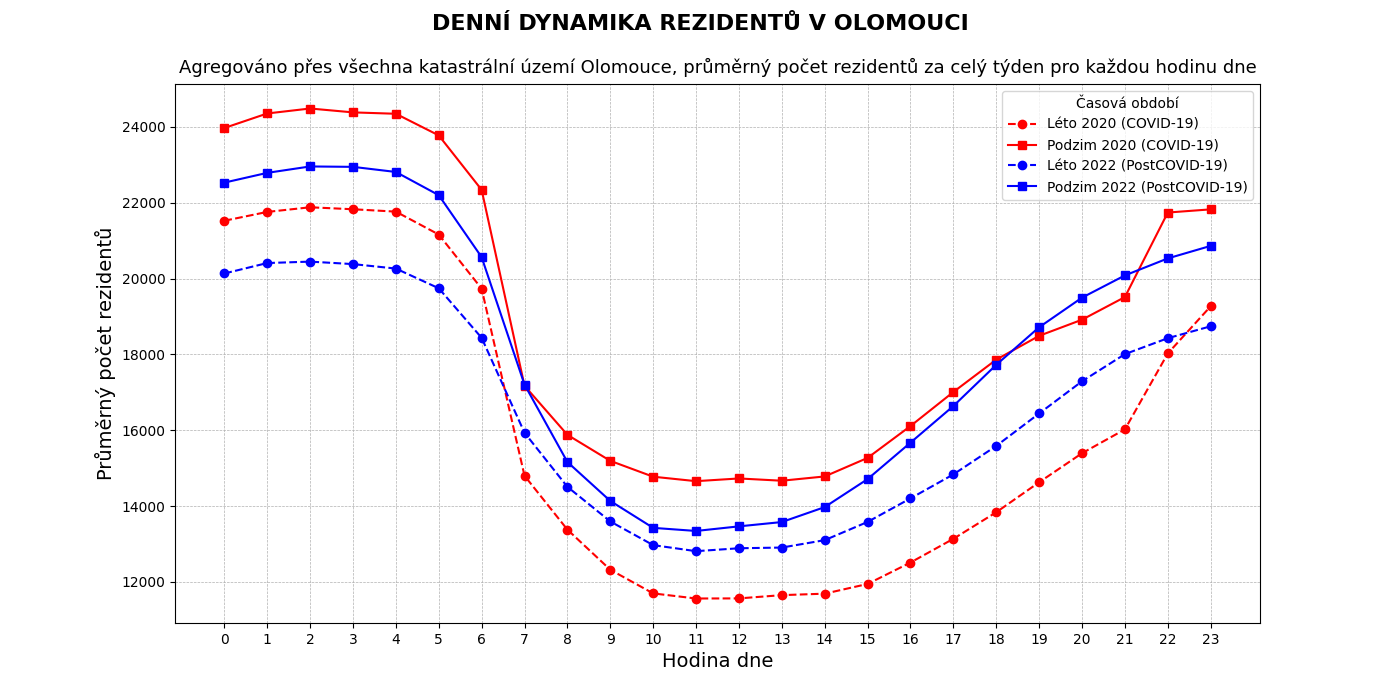
Cílem EDA bylo identifikovat sezónní trendy, typické vzorce a rozdíly v prostorovém a časovém rozložení jednotlivých kategorií osob. Tento přístup využívá vizualizační a deskriptivní techniky k objevování vztahů mezi proměnnými, anomálií nebo outlierů (Tukey, 1977). EDA je flexibilní přístup, který nevyžaduje předem stanovené hypotézy, což umožňuje intuitivně prozkoumat data a objevit nové souvislosti. Základními nástroji EDA jsou například histogramy, box-ploty, scatter-ploty nebo heatmapy, které poskytují rychlý přehled o základních charakteristikách dat (Behrens, 1997).
Prostorová autokorelace
Další metodou použitou v této práci byla prostorová autokorelace, která měří vztah mezi hodnotami jedné proměnné v závislosti na jejich prostorové blízkosti. Pomocí Lokálního Moranova indexu, který byl poprvé vyvinut Anselinem (1995), bylo možné kvantifikovat prostorovou závislost a identifikovat oblasti s konkrétními prostorovými vzory, jako jsou shluky vysokých nebo nízkých hodnot a outliery. Tato metoda je cenná pro analýzu geografických dat, protože umožňuje detekovat prostorovou asociaci mezi hodnotami proměnných v sousedních prostorových jednotkách (Getis & Ord, 1992).
Shluková analýza (Multivariate Clustering)
Na základě kombinace EDA a metod shlukování byla vytvořena typologie obcí a katastrálních území. Pomocí shlukové analýzy (multivariační analýzy) bylo možné identifikovat regiony s podobnými charakteristikami mobility. Pro tuto analýzu byly použity algoritmy K-means a K-medoids, které automaticky seskupují objekty na základě jejich podobnosti (Everitt et al., 2011). K-means minimalizuje rozptyl mezi shluky a přiřazuje objekty do předem definovaných skupin na základě jejich euklidovské vzdálenosti. K-Medoids je alternativní metoda, která je citlivější na extrémní hodnoty a používá jako střední hodnotu medián místo průměru, což je vhodné pro heterogenní data (Kaufman & Rousseeuw, 2005).
Typologie
Typologie, jako vědecká metoda kategorizace, byla použita k seskupení obcí na základě jejich prostorového a časového chování obyvatel. Tento přístup pomohl lépe porozumět dynamice pohybu populace a rozdělit regiony do typů podle specifických vzorců mobility. Tento typologický přístup se využívá k systematickému třídění objektů nebo jevů na základě jejich podobných vlastností, což usnadňuje studium vzorců a vztahů mezi nimi (Hampl, 2000).
Postup zpracování