Převod dat mezi SMI a programem Ogama
Export z SMI
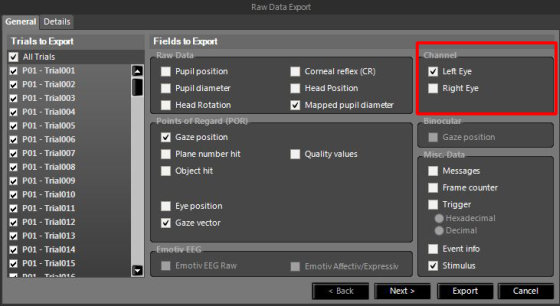
Pro přenos dat ze softwaru SMI je nejprve nutné data upravit do tvaru, který akceptuje Ogama. Tento proces začíná exportem naměřených dat. V okně s možnostmi exportu dat je potřebné vybrat záznamy naměřené pouze pro jedno oko. Ogama neumí pracovat se záznamy obsahující informace o pohybu obou očí. To vede v důsledku k zanedbatelnému snížení přesnosti, ale naopak k výraznému zvýšení rychlosti výpočtu neboť je zpracováváno pouze poloviční množství dat a zároveň nároků na paměťový prostor. Nastavení okna pro export záznamů se zvýrazněným místem výběru dat naměřených pro určité oko je na obrázku 5.1. Není důležité, zda se jedná o pravé či levé. Kromě této volby je nutné provést výběr volby „Gaze position“. Tento parametr vloží do výstupního textového souboru polohu zraku, která je nutná pro výpočet fixací.
Takto vyexportovaná data je nutné modifikovat do podoby umožňující přímý import do Ogamy. K tomuto účelu byl využit skript od Kristien Ooms v jazyku BlueJ. Pro jeho spuštění je nutné mít nainstalovaný balík Java Development Kit a prostředí BlueJ. Ve složce obsahující samotný skript se nachází složka s názvem „dataSMI“. Do ní musí být vložena vyexportovaná data z produktu SMI. Je vhodné provést jejich přejmenování do následujícího tvaru cokoliv_oznaceniRespondenta_cokoliv.txt. Tuto strukturu je potřebné pro správný běh programu dodržet. V části cokoliv může být obsažena libovolná informace, pro výsledek není důležitá. Jednotlivé části musí být odděleny podtržítky.
Obsah nacházející se mezi podtržítky s označením oznaceniRespondeta přejímá výsledný soubor pro následný import za svůj název. Je tedy vhodné ho formulovat tak, aby byla umožněna identifikace respondenta v průběhu zpracování programem Ogama. Po dokončení kopírování souborů a úpravy jejich názvu přichází samotné spuštění skriptu. V nově zobrazeném okně je nutné pravým klikem myši na objekt „Converter“ vyvolat nabídku a v ní vybrat příkaz „new Converter()“. Následně se zobrazí dialogové okno kterému není potřeba věnovat pozornost a stačí pouze odkliknout volbu „OK“. Po úspěšném dokončení tohoto skriptu dochází k vytvoření samotných souborů pro import do Ogamy. Jejich umístění je ve složce „dataOgama“.
Před zahájením importu je však nutné provést uspořádání obsahu soboru ZERO.txt, který slouží k nastavení rozsahů experimentu. Pořadí určuje atribut STIMULUSID a hodnoty jsou uspořádány vzestupně. Pro tento účel byl sestaven algoritmus v jazyku Microsoft Visual Basic, který tento proces zautomatizuje. Po jeho spuštění stačí pouze provést výběr konkrétního ZERO souboru a po dokončení operace je již obsah podle potřeby uspořádán.
Import do programu Ogama
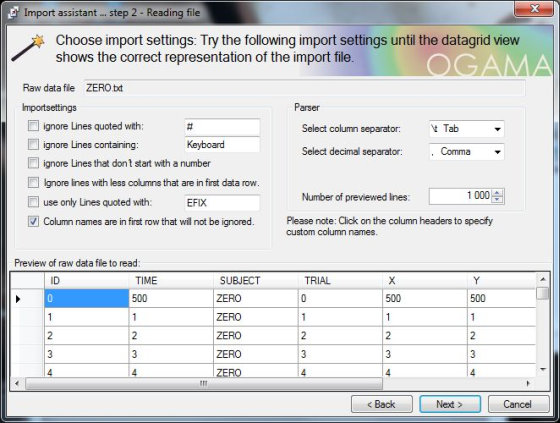
Po úpravě formátu dat je možné zahájit samotný import. Ten se provádí přímo v programu Ogama. Nejprve je nutné vybrat z nabídky „Tools“ funkci „Import gaze or mouse samples“. Po jejím vybrání dojde k otevření nového dialogového okna obsahujícího informace pro úspěšný import. Pokračujeme volbou tlačítka „Start“. Ve výběrovém okně se musíme připojit ke složce s již upravenými daty. Tento postup umožňuje import pouze po jednotlivých respondentech, není možné hromadné přidání dat. Nejprve je nutné vybrat vytvořený a uspořádaný soubor „ZERO.txt“, Ogama zobrazí dotaz, zda má využít pro import soubor s nastavením. Zatím však nedošlo k jeho vytvoření, proto je nutné pokračovat volbou „Ne“. Na obrazovce se objeví okno s prvními možnostmi nastavení. Na ní je možno zvolit parametry jenž popisují strukturu dat určených k importu, jako je použitý oddělovač dat a podobně. Z možností v levé části okna je vybrána pouze poslední „Column names are in first row that will not be ignored“. Jejím výsledkem je načtení záhlaví souboru s názvy sloupců. V právě části se nachází možnosti separátoru mezi záznamy. Jako oddělovač sloupců tedy volba „Select column separator“ je nutné vybrat tabulátor – volba „\t Tab“. Pod ním se nachází volba oddělovače číselných hodnot s popisem „Select decimal separator“. Zde je použita tečka, proto z nabízených možností je zapotřebí vybrat „. Comma“. Poslední parametr ovlivní pouze množství záznamů zobrazených v náhledu. Tento náhled může sloužit i pro kontrolu nastavení zda jednotlivá data jsou uspořádána do požadované struktury. Po dokončení nastavení tohoto okna lze pokračovat přes tlačítko „Next“.
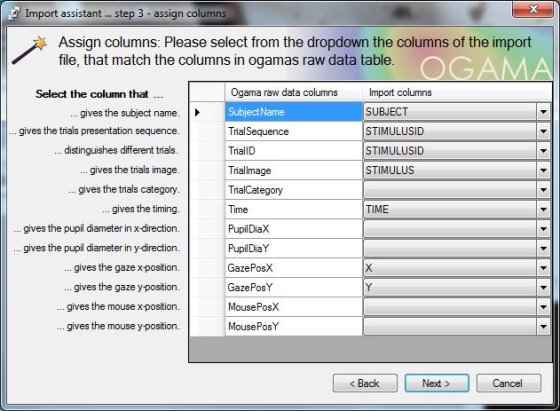
To zobrazí další okno možností, ve kterém je možné každému sloupci importovaných dat přiřadit význam, se kterým pracuje samotná Ogama. Jedná se o přiřazení těchto parametrů: označení respondenta, trialu, název snímku použitého jako trial, časové údaje popisující dynamiku experimentu a naměřené souřadnice oka. Označení pro identifikaci respondenta se nachází pod parametrem „SubjectName“ v datech se jedná o sloupec se záhlavím „Subject“. Údaje o trialu se ukrývají pod parametry „TrialSequence“ a „TrialID“. U obou je nutno vybrat sloupec dat s označením „STIMULUSID“. Název obrázku, který byl zobrazen jako stimul, je uložen ve sloupci „Stimulus“. Ogama tuto informaci označuje parametrem „TrialImage“. Poslední zdrojové údaje se týkají naměřených pozic oka. Jejich označení je X a Y. Tyto souřadnice je nutno připojit k parametrům „GazePosX/Y“. Souřadnice si musí vzájemně odpovídat, to znamená souřadnice X v importovaných datech slouží jako vstup souřadnic X pro program Ogama a naopak. V případě záměny by zobrazená data nekorespondovala se skutečným průběhem experimentu. Po dokončení výběru je nutné pokračovat tlačítkem „Next“.
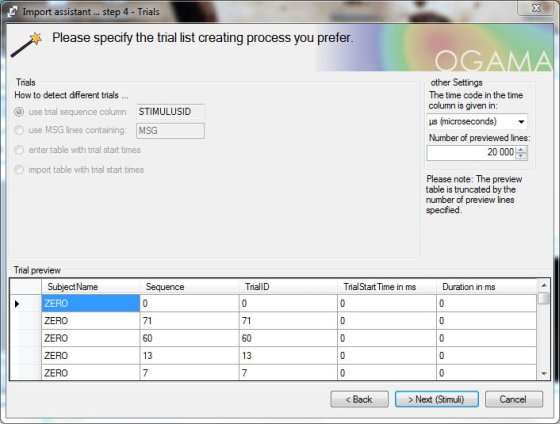
V dalším okně lze provést kontrolu správnosti rozdělení dat k jednotlivým atributům v připraveném náhledu. Také je zde zahrnuta volba jednotky importovaných časových údajů. Ty se z programu SMI nachází ve formátu mikrosekund. Proto v nabídce s výběrem tohoto parametru vybereme „µs (microseconds)“. Poté je možno pokračovat opět přes tlačítko „Next“.
Poté již stačí spustit import tlačítkem „Start Import“. Aby nebylo nutné neustále vyplňovat stejné parametry pro import dalších respondentů je možno toto nastavení uložit do externího souboru a poté vždy na začátku importu provést jeho načtení. Tento soubor lze použít i pro další experimenty pokud bude struktura dat zachována. Pro import dalších respondentů je postup nutné opakovat, díky externímu souboru s nastavením je však tento proces značně urychlen.