
Aplikace asociačních pravidel na prostorová data
Diplomová práce | Lenka TRNOVÁ | Olomouc 2020
Úvod
Asociační pravidla je jedna z metod data miningu, díky které lze nalézt mezi daty asociace, které nemusí být na první pohled zřetelné. Primárně se jedná o neprostorová data, ale v rámci této práce byla snaha hledat asociační pravidla pro prostorová data. Prostorová data nelze ale nahrát přímo do softwaru, který umožňuje generovat asociační pravidla. Prostorová data je nutné předpřipravit. V teoretické části dojde k seznámení se s asociačními pravidly, jejich děleními a zmínění dostupných prací, které se tímto tématem zabývaly. Dojde k seznámení se s dostupnými nástroji, které pracují s asociačními pravidly. Část z nich bude následně použito v praktické části, ve které se otestuje jejich funkcionalita. Na základě vytvořené testovací prostorové datové sady bude zvolený SW Orange, ve kterém se bude nadále pracovat.
V práci jsou sepsány celkem tři případové studie, ve kterých je nalezen postup, jak upravit prostorová data v QGIS, tak, aby bylo možné pro ně hledat asociační pravidla. Součástí práce je také zobrazení asociačních pravidel zpět do prostoru pomocí mapových výstupů s bodovou metodou. Pro ulehčení práce byl také vytvořen pomocný Python skript, který je spustitelný v QGIS. Závěrečným výstupem práce je step-by-step návod, ve kterém je podrobné sepsán celý postup od úpravy dat až po výslednou vizualizaci výsledných asociačních pravidel.
Cíle práce
Cílem diplomové práce je vhodný způsob, jak aplikovat asociační pravidla na prostorová data. Způsob bude následně aplikován na praktické případy. Dílčí částí bude nalezení technického řešení v open-source prostředí.
V teoretické části bude představení data miningu (DM) jako metody získávání užitečných informací z dat. Následovat bude samotný rozbor asociačních pravidel a k čemu slouží. Dílčí část rešerše bude zaměřena na analýzu dostupných prací týkajících se aplikace asociačních pravidel na prostorová data. Dále dojde k rozboru dostupných technických řešení. Z těchto řešení se následně zvolí jedno, které bude využito do praktické části.
V praktické části dojde k vytvoření uceleného postupu, jak upravit prostorová data do takové podoby, aby bylo možné vygenerovat asociační pravidla. Dále budou vytvořena testovací data, která budou sloužit k ověření funkčnosti vytvořeného postupu. Po ověření funkčního postupu se vytvoří 3 případové studie týkající se prostorových dat, pro které se budou hledat asociační pravidla. Cílem bude naleznout taková pravidla, která nejsou na první pohled patrná, nejsou tedy frekventovaná. Na případových studiích bude demonstrován vhodný postup a nasazení softwaru (SW).
Výsledkem práce budou vygenerována jak asociační pravidla, tak i preferenční pravidla včetně výjimek z asociačních pravidel. Nedílným výstupem práce bude step by step návod, jak prostorová data upravit a jak jednotlivá asociační pravidla vygenerovat. Cílem práce není nalézt co nejracionálnější asociační pravidla, ale nalézt způsob, jak prostorová data lze upravit, aby toho bylo možné docílit.
Metody
Prostorové analýzy
V rámci praktické části bylo použito několik prostorových metod, z nichž nejčastější z nich byla tvorba obalové zóny (bufferu) kolem prvků. Jedná se o nástroj spadající do kategorie analýzy blízkosti. Pomocí něj lze získat informace o okolí prvku. Jedná se o oblast, která je uživatelem nadefinovaná pomocí vzdálenosti (např. v metrech). Nástroj vytvoří takovou oblast, která je od všech uzlů prvků vzdálena právě tuto vzdálenost.
Dalším velmi využívaným nástrojem je připojení dat podle umístění (spatial join). Nástroj umožňuje převést atributy jedné datové sady do druhé na základě jejich prostorové vazby. Prostorová vazba je předem definovaná. Může se jednat o protínání vrstev, dotyk vrstev na hranici, jeden prvek se nachází uvnitř prvku druhé vrstvy atd.
V rámci sjednocení dvou vrstev stejné tématiky, kdy jsou data v bodové a zároveň polygonové podobě bylo využito nástroje pro tvorbu centroidů (centroids). Dalším krokem bylo spojení těchto vrstev (merge vector layers).
V neposlední řadě bylo využito kalkulátoru polí (field calcultor) pro zapisování vybraných hodnot do nově vytvořených atributových sloupců.
Skriptování
Pro tvorbu skriptu bylo využito programování v jazyce Python, jež je podporovaným jazykem pro tvorbu skriptů do QGIS. Python jazyk je označován jako jeden z nejjednodušších programovacích jazyků. Jeho výhodou je jednoduchá syntaxe a velmi přehledný kód. V poslední letech se Python stává stále oblíbenějším jazykem pro programování nejrozmanitějších programů a nástrojů.
Postup práce
Obr. 1 popisuje diagram postupu diplomové práce. První krok představuje rešerši knižních zdrojů, odborných článků a elektronických studií. Tyto práce budou mimo jiné sloužit jako podklad pro nalezení vhodného SW (software) pro generování pravidel. Součástí rešerše bude také snaha nalézt práce týkající se přímo aplikace na prostorová data. Díky tomu bude možné získat představu o tom, jaký typ dat, resp. jaká metoda úpravy prostorových dat je použitelná. Následně bude připravena testovací datová sada, která bude sloužit pro seznámení se s dostupným technickým řešením. Ověří se jeho funkčnost a spolehlivost. Tato testovací datová sada bude zcela smyšlená a bude pouze experimentální.
Do praktické části bude následně zvoleno takové technické řešení, které bude z mnoha ohledů nejvhodnější. V tomto technickém řešení bude provedená veškerá práce, co se generování asociačních pravidel týče. Součástí práce je vytvoření tří případových studií, kde budou hledána asociační pravidla. Datové sady bude potřeba na základě nastudované literatury jistým způsobem upravit tak, aby na ně bylo možné nasadit zvolený nástroj. Úpravou se rozumí využití prostorových analýz v rámci QGIS viz Prostorové analýzy. Nedílnou součástí praktické částí je vytvoření skriptu, který poslouží k ulehčení vizualizace jednotlivých asociačních pravidel. Také se vytvoří jednotný vizuální styl, který poslouží pro mapové výstupy zobrazující vygenerovaná asociační pravidla.
V závěru práce bude sepsán přehledný postup úpravy dat až po samotné vygenerování asociačních pravidel. Postup bude sloužit jako manuál pro aplikaci na vlastní datové sady. Manuál musí být sepsán tak, aby bylo možné všechny jeho kroky zreplikovat. V poslední fázi budou vytvořeny náležitosti jako je poster a webové stránky, informující o výsledcích dosažených v této diplomové práci.
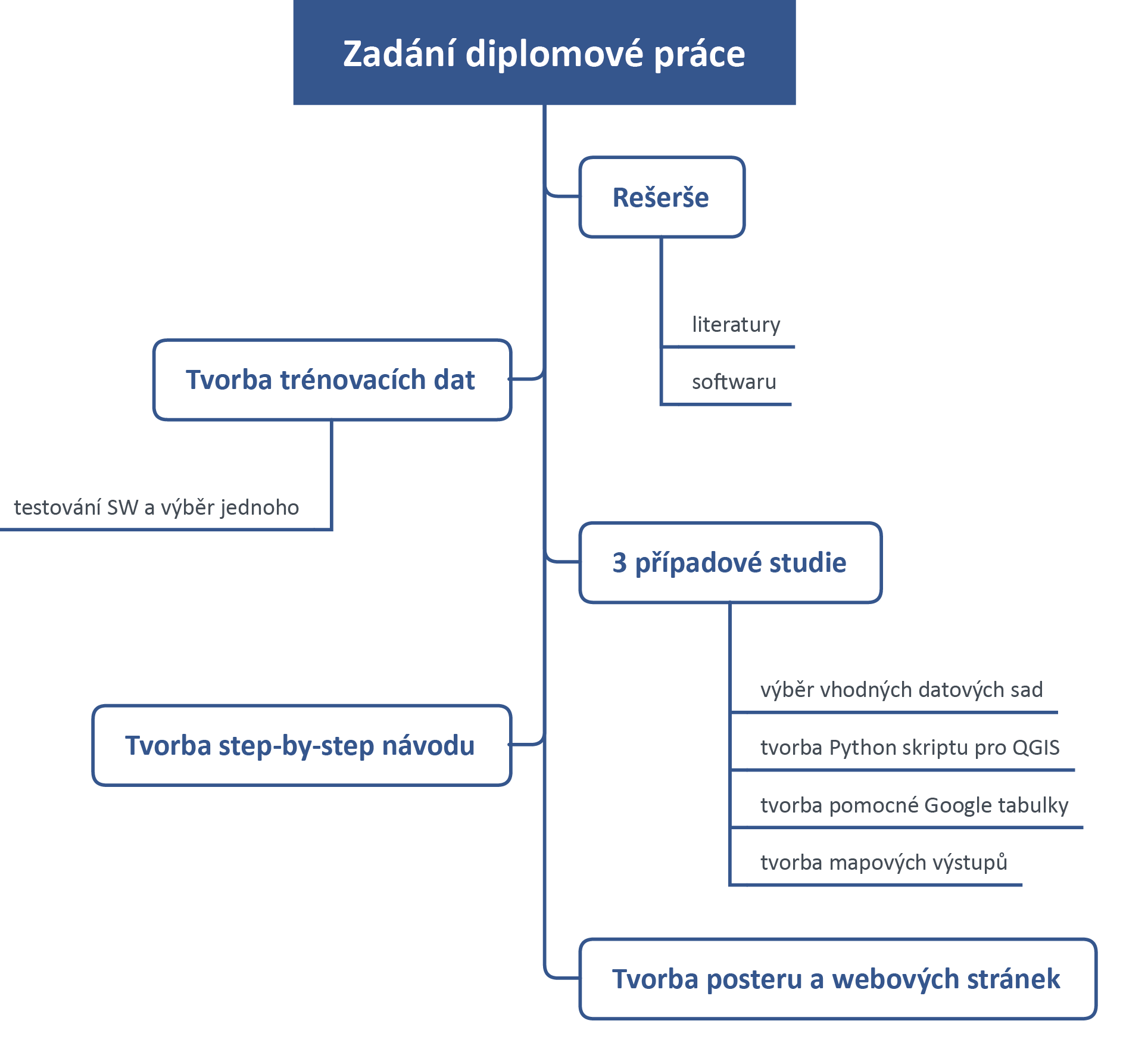
Obr. 1 Diagram postupu práce
Výsledky
Výsledkem práce jsou následující výstupy:
Univerzální modely, které uživatel může použít libovolně a opakovaně na základě povahy použitých datových sad.



Součástí práce je také vytvoření jednoduché výsledné mapy. V případových studiích byly nalezeny i jiné způsoby vizualizace – např. pomocí strukturních diagramů. Primárně se ale jedná o jednoduchou bodovou metodu, díky které lze vždy zobrazit asociační pravidlo společně s prvky, které jej splňují.

Obr. 2 Ukázka strukturního diagramu
Kromě jednoduchých map byla také vytvořena interaktivní mapa v prostředí knihovny Leaflet, jejíž ukázku můžete vidět ZDE.
Interaktivní mapa je jednoduchá, v seznamu vrstev je možné vybrat, které z uvedených asociačních pravidel chce uživatel zobrazit. Je doporučené vždy zobrazit pouze jedno z nich, jelikož jeden prvek může splňovat více pravidel. Po kliknutí na vybraný prvek se zobrazí jednoduché vyskakovací okno s informací kolik asociačních pravidel daný prvek splňuje.
Pro vizualizaci zpátky do prostoru je potřeba pravidla upravit tak, aby každá hodnota atributu byla uvozena jednoduchými uvozovkami. Současně mezi každou podmínkou musí být vepsán logický operátor „AND“. Manuální úprava není nikterak složitá, ale pro zjednodušení práce byla vytvořena tabulka v Google Tabulkách.
def rule_based_style(layer, symbol, label, expression, color):
root_rule = renderer.rootRule()
rule = root_rule.children()[0].clone()
rule.setLabel(label)
rule.setFilterExpression(expression)
rule.symbol().setColor(QColor(color))
root_rule.appendChild(rule)
layer = iface.activeLayer()
symbol = QgsSymbol.defaultSymbol(layer.geometryType())
renderer = QgsRuleBasedRenderer(symbol)
# lokace souboru k nacteni
f1 = open("d:/CSV-podminky.csv", "r", encoding='utf-8', errors='ignore')
# nadefinovane barvy
colours = ['#66c2a5','#fc8d62','#8da0cb','#e78ac3','#a6d854','#ffd92f','#e5c494', '#b3b3b3']
cislo=-1
cisloRange = len(colours)
for line in f1.readlines():
if cislo<=cisloRange:
cislo+=1
if '=' in line:
rule_based_style(layer, symbol, str(line), line, colours[cislo])
# nastaveni symbologie pro ostatni prvky
rule_based_style(layer, symbol, 'nesplňuje pravidlo', 'ELSE', '#00F0F8FF')
print('Konec skriptu')
layer.setRenderer(renderer)
layer.triggerRepaint()
iface.layerTreeView().refreshLayerSymbology(layer.id())
V praktické části byl nalezený způsob, jak pro prostorová data hledat asociační pravidla a zároveň bylo umožněno výsledná pravidla zobrazit zpátky do prostoru. Pro snadnou replikaci postupu byl sepsán step-by-step manuál , který detailně popisuje jednotlivé kroky práce. Lze si níže stáhnout samotný návod v PDF formátu nebo v ZIP archivu společně s použitými daty a vzorovými výstupy.
Obr. 3 Ukázka step-by-step návodu
Závěr
Cílem diplomové práce bylo nalézt funkční způsob úpravy prostorových dat tak, aby bylo možné pro ně naleznout asociační pravidla. Asociační pravidla by měla primárně přinášet informace o vazbách mezi prvky, které nemusí být na první pohled zřetelné.
Teoretická část práce se zabývá hledáním dostupných odborných prací, které se tomuto problému věnovaly. Zároveň zde byla snaha nalézt co nejvíce programů, které umožňují generovat asociační pravidla. Takové programy umějí pracovat pouze s neprostorovými daty, proto bylo nutné hledat možnou předúpravu prostorových dat.
V praktické části byly otestovány vybrané programy pomocí vytvořených testovacích dat. Dále byly hledány vhodné datové sady a jejich kombinace tak, aby bylo možné získat co nejzajímavější asociační pravidla. Na základě vybraných datových sad byly vytvořené celkem tři případové studie, které využívají vlastní připravený model na úpravu prostorových dat.
Výsledkem takové úpravy je jedna atributová tabulka, kterou lze bez problému nahrát do vybraného SW Orange. V něm došlo ke hledání asociačních pravidel, které lze díky pomocné Google tabulce a předchystanému PyQGIS skriptu nahrát zpět do prostoru. Pravidla zde vystupují jako podmínky pro symbologii a v mapovém výstupu lze zobrazit prvky, které dané pravidlo splňují, popř. naopak nesplňují. Také byl nalezen jiný způsob vizualizace, a to tvorba strukturního diagramu. Díky němu je možné zobrazit více asociačních pravidel zaráz a zároveň lze získat informaci o tom, kolik pravidel splňuje konkrétní prvek.
Na základě nalezeného postupu byl vytvořený step-by-step návod, který sumarizuje celý nalezený postup od úpravy prostorových dat až po výsledný mapový výstup. Součástí návodu jsou celkem tři modely, které lze opakovaně využít pro konkrétní úpravu dat.
Cíl práce byl na základě tří případových studií a vytvořeného návodu splněný. Díky návodu je možné upravit vlastní vybrané datové sady a lze s nimi dále pracovat.
Summary
The Master’s thesis deals with the generating association rules for selected spatial datasets. Association rules are part of data mining, which helps obtain new information from the dataset. All of this information may not be obvious at first glance, so it is important to pay attention to the rules that are not frequent. Thanks to them it is possible to learn about spatial colocation between spatial elements, which may not be similar to each other. To generate spatial data, it needs to preprocess them. Part of the work is focused on finding more ways how to achieve it. All work is done in open-source software. Many software can generate association rules. In case studies, only software called Orange has been used. Also work is focused on visualization of the resulting rules back into spatial. The complementary tool is MS Excel, which simplifies the modification of association rules. Also, a script for QGIS (PyQGIS) has been developed to import modified rules as conditions for visualization on the map. The conclusion of the thesis is summed up with a clear step-by-step manual with the whole procedure, from data preprocessing to the final map with association rules.
Kontakt


© Lenka TRNOVÁ 2020. All rights reserved. Design by: HTML5 UP.