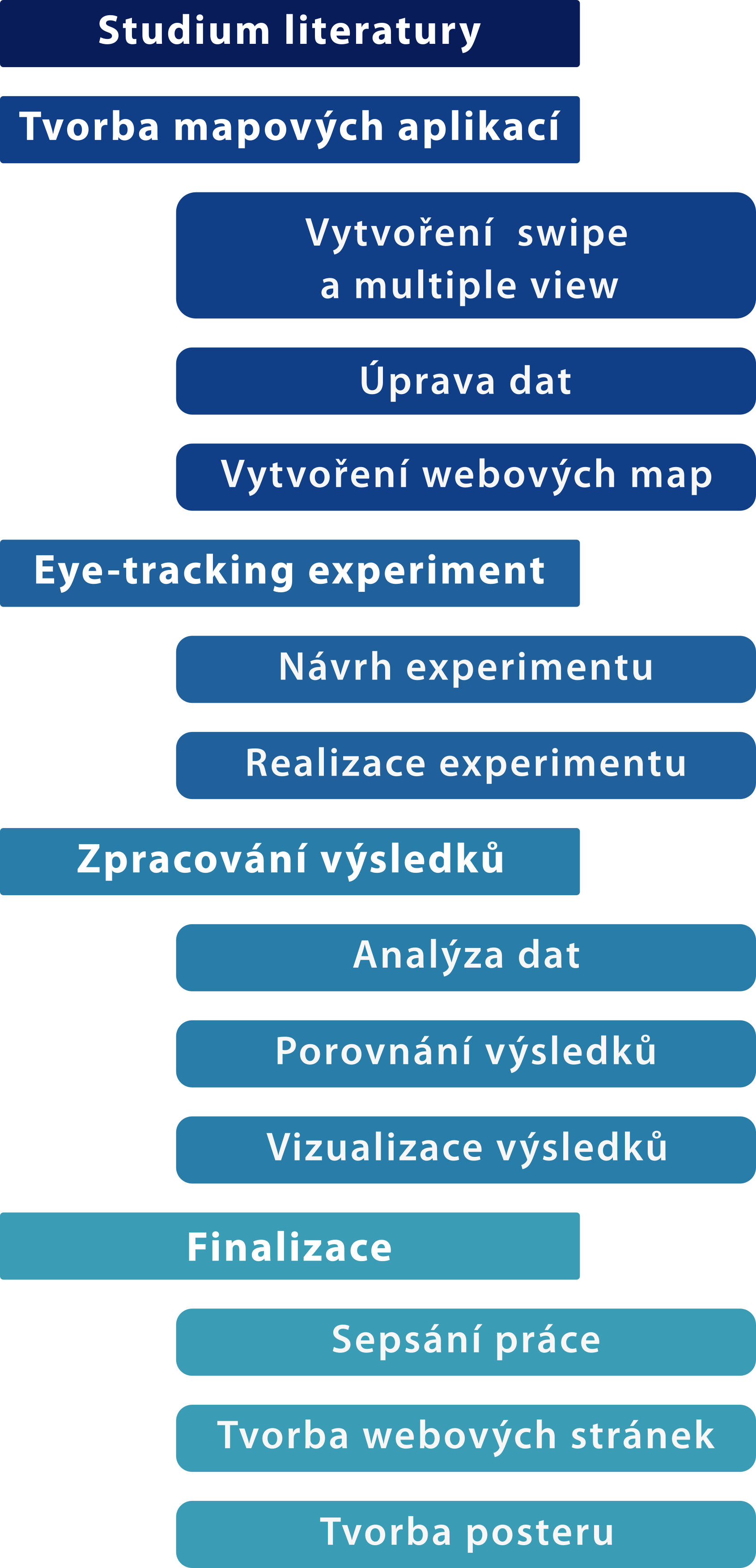
Postup práce
Prvním krokem diplomové práce bylo studium odborné literatury. Zde bylo hlavním úkolem seznámení s tématem a prozkoumání dostupných metod pro srovnávání map. Následovala samostatná práce, při které byly nejprve vytvořeny mapové aplikace pro metodu multiple view a swipe. Tyto dvě metody jsou nejčastěji používané pro porovnávání geografických dat ve webovém prostředí. Po vytvoření aplikací byla vybrána sociologická data, která byla v mapách zobrazena. Pro práci byla zvolena sociologická data České republiky a států Evropské unie a historické mapy města Olomouce. Data byla nejprve upravena pro účely práce a následně byla implementována do prostředí webové mapové aplikace. Dalším krokem práce bylo navržení eye-tracking experimentu porovnávajícího zvolené vizualizační nástroje. Experiment byl poté realizován na 45 respondentech a doplněn o dodatečné informace pomocí psychologického dotazníku. Následovalo vyhodnocení experimentu a analýza dat. Posledním krokem práce byla výsledná interpretace výsledků a zhodnocení použitých vizualizačních nástrojů.
Použitá data
Jako kartografický podklad byla použita vrstva obcí s rozšířenou působností z databáze ArcČR 4.1. Pro státy Evropské unie se jednalo o vrstvu obsahující hranice NUTS 2 (Nomencature of Units for Territorial Statistics) . Pro tvorbu map byla použity sociologická data pro Českou republiku a státy Evropské unie. Data pro Českou republiku byla použity z databáze DataPAQ, což je unikátní prohlížečka vzdělávacích a sociálních dat vyvinuta organizací PAQ Research. Tyto data jsou poskytována na různých úrovních (kraje, okresy, obce s rozšířenou působností) a ve dvou formátech (.xls a .csv). Data byla poté upravena a vizualizována. Datová sada využitá pro tvorbu map států Evropské unie byla data z databáze Eurostatu. Tato data poskytují široké spektrum sociálních a ekonomických ukazatelů, které umožňují porovnání mezi jednotlivými státy Evropské unie. Pro tuto práci byla využita především sociologická data. Stejně jako v případě dat z DataPAQ byla provedena jejich úprava a následná vizualizace. Poslední data pro tvorbu map byla poskytnuta katedrou geoinformatiky Univerzity Palackého v Olomouci. Jedná se o dvě historické mapy z 19. a 20. století zobrazující Město Olomouc. Stejně jako u sociologických dat byly i tyto mapy upraveny pro potřeby diplomové práce. Data o účastnících byla sesbírána v rámci eye-tracking experimentu provedeném v eye-tracking laboratoři na katedře geoinformatiky Univerzity Palackého v Olomouci, pomocí zařízení Tobii Pro Spectrum 300. Kromě informací o očních pohybech účastníků, byl experiment doplněn o informace o kognitivním stylu pomocí psychologických dotazníků prostřednictvím platformy Hypothesis.
Použité programy
Pro přípravu dat byl primárně využit program Microsoft Excel, ve kterém byla sociologická data upravena a připravena pro další zpracování. Následně byla tato data spojena s prostorovými vrstvami v prostředí ArcGIS Pro. Pro generalizaci hranic České republiky a Evropské unie byl použit online nástroj Mapshaper, jenž umožňuje interaktivní úpravy formátů jako Shapefile, GeoJSON, TopoJSON či CSV. Pro propojení sociologických údajů s geometrickými daty byl dále využit QGIS, kde byly výstupní vrstvy exportovány ve formátu GeoJSON. Úpravy historických mapových podkladů probíhaly v programu Inkscape a následně byly mapy importovány do nástroje MapTiler Engine, který umožňuje generování mapových dlaždic v rastrové i vektorové podobě. Vygenerované dlaždice byly následně nasazeny do webového prostředí. Vlastní tvorba webové mapové aplikace probíhala v prostředí Notepad++ za využití knihovny Leaflet, která poskytuje široké možnosti pro interaktivní práci s mapovými vrstvami. Pomocí Leafletu byly realizovány varianty vizualizace zahrnující metody multiple view a swipe. Pro tvorbu barevných stupnic byl použit nástroj COLORBREWER. Eye-trackingový experiment a následné zpracování záznamu probíhaly v softwaru Tobii Pro Lab. Statistická analýza a tvorba grafů byla realizována v prostředí RStudio . K vizualizaci očních fixací a sekvenční analýze byl využit nástroj GazePlotter, který umožňuje generování sekvenčních grafů i přechodových matic mezi jednotlivými oblastmi zájmu (AOI). Pro tvorbu skriptů v jazyce R a úpravu webových komponent byl jako podpora při ladění kódu využit jazykový model ChatGPT, který sloužil jako konzultační nástroj v průběhu programování a statistické analýzy.
Statistické metody
Statistická analýza získaných dat byla provedena v prostředí RStudio. Cílem bylo ověřit, zda existují statisticky významné rozdíly v délce řešení úkolů a chybovosti mezi vizualizačními metodami (multiple view a swipe), mezi skupinami respondentů a mezi typy úloh. Nejprve bylo provedeno porovnání času plnění úkolů mezi skupinami respondentů (Carto, Socio, Random). Respondenti byli rozděleni do tří skupin podle svého studijního zaměření. První skupinu tvořili studenti a zaměstnanci Katedry geoinformatiky, označeni jako Carto. Druhou skupinu tvořili studenti sociologie, označeni jako Socio. Třetí skupinu, označenou jako Random, představovali náhodně vybraní studenti univerzity, kteří nepatřili do žádné z předchozích skupin. Pro tento účel byl použit Wilcoxonův test. Tento test byl použit také pro porovnání časů mezi metodami multiple view a swipe pro každou úlohu. Pro porovnání mezi úlohami zaměřenými na Českou republiku, Evropskou unii a město Olomouc byl opět použit Wilcoxonův test. Pro analýzu rozdílů v délce řešení mezi různými typy úloh (Difference, Points, Region) byl použit Kruskal-Wallisův test. V případě, že test ukázal statisticky významný rozdíl, byl následně proveden Dunnův post-hoc test s Bonferroniho korekcí. Dále byly výsledky analyzovány také pro jednotlivé typy úloh zvlášť, kde byl opět aplikován Wilcoxonův test, aby se ověřilo, zda metoda vizualizace (swipe vs. multiple view) měla vliv na čas řešení daného typu úkolu. V poslední části analýzy byly porovnávány časy věnované jednotlivým oblastem zájmu (AOI) mezi dvěma metodami u vybraných úloh. Pro každou odpovídající dvojici oblastí (např. MapLEFT ve swipe vs. MapLEFT v multiple view) byl opět použit Wilcoxonův test. Výsledky byly doplněny o průměrné a mediánové hodnoty, a p-hodnoty byly upraveny metodami Bonferroni a FDR (False Discovery Rate), aby se minimalizovalo riziko vzniku chyb. Kognitivní styl respondentů byl určen pomocí počítačového Navonova testu, který vyhodnocoval rychlost reakce na globální (celkové) a lokální (detailní) podněty. Na základě rozdílů v reakčních časech byl vypočítán relativní index, který byl upraven o průměr celé skupiny. Pomocí směrodatné odchylky byly respondenti rozděleni do tří kategorií: analytický styl (rychlejší reakce na detaily), holistický styl (rychlejší reakce na celek) a neutrální styl (vyvážené zpracování). Pro porovnání výkonnosti mezi skupinami respondentů s různým kognitivním stylem byl použit Kruskal-Wallisův test. Významnost rozdílu mezi metodami byla analyzována pomocí Wilcoxonova párového testu. Pro porovnání rozložení kategorií kognitivních stylů napříč skupinami byl nejprve použit chí-kvadrát test, jehož výsledek byl kvůli nízkým četnostem doplněn přesnějším Fisherovým testem.
Postup zpracování